




INTRODUCTION
Holstein-Friesian cattle have been selected intensively during the last millennia, especially in the last five decades after the breeding programs were started in the 1960s (Skjervold and Langholz, 1964; Mwai et al., 2015). Holsteins have been selected for milk yield and milk composition, which was progressed through the development of reproductive technologies like pedigree evaluation of bulls, artificial insemination, embryo transfer and the like. Recently, genomic selection have accelerated the selection process (Catillo et al., 2001; Goddard and Hayes, 2007). This selection has resulted in an increase in the frequency of favorable alleles affecting selected traits. The selection will have also increased the frequency of alleles of neutral markers in linkage disequilibrium with the favorable alleles (Smith and Haigh, 1974). In addition, identifying genomic regions subject to selection could reveal the mutations responsible for improved production (Boitard and Rocha, 2013). However, the current selection trends have been ignored. Thus, we focused on the current selection trends and selection coefficient based on single nucleotide polymorphisms (SNPs).
To predict each SNPŌĆÖs selection coefficient associated with Holstein milk-related traits, we used FisherŌĆÖs fundamental theorem of natural selection, which states that the rate of increase in fitness of any organism at any time is equal to its genetic variance in fitness at that time (Hartl, 1988). We can calculate the relative selection coefficient based upon this theorem and the linear additive model. The model is the best linear unbiased prediction (BLUP). BLUP was originally proposed by Henderson (Henderson, 1975). The predicted SNP effects from BLUP were used to calculate the additive genetic variances of the SNPs. FisherŌĆÖs theorem links the additive genetic variance to the selection coefficient (Hartl, 1988). The selection coefficient is dependent on the phenotypes and their units. So it can be called ŌĆ£expected relative current selection coefficientŌĆØ. ŌĆ£ExpectedŌĆØ implies that the selection coefficient is the expected value in the F1 generation. ŌĆ£RelativeŌĆØ means that it is dependent on the unit of phenotypes. Thus, it was recalibrated by the maximum value. The predicted value of the selection coefficient could be the actual value if selection were performed only using breeding values of a given trait and selection followed FisherŌĆÖs theorem.
The genes containing highly significant SNPs were obtained using Ensembl website (Flicek et al., 2011). The BLUP-based relative selection coefficient has the current selection information. We analyzed the ontology of the genes containing the highly significant SNPs (top 1% or p-value <0.01). The P-values were obtained under the normal assumption of selection coefficient.
MATERIALS AND METHODS
Materials
Female Holsteins were randomly collected in Korea. The phenotypes were milk yield, fat and protein contents with parity 1 and the number of Holstein with phenotypic values in the data was 462. Genomic DNAs from Holstein cows were genotyped using Illumina 50K SNP Beadchip (Illumina, San Diego, CA, USA) following the standard protocol. A total number of 41,099 genotyped SNPs were imputed using BEAGLE version 4.0 (Browning and Browning, 2009) and filtered using minor allele frequency (MAF<0.05), Hardy-Weinberg equilibrium (HWE p<0.001), missing genotype data (>0.1) and we excluded the SNPs on the sex chromosome. After these quality controls, there remained 37,854 autosomal SNPs. Individual animals with missing phenotypic values were excluded before filtering, e.g., filtering by MAF.
Prediction of SNP effects for milk production traits
The BLUP model is the following formula:
Where y was the vector of phenotypic values, X and Z were the incidence matrices, b and u were vectors of fixed and random effects, respectively. Random effects and residual errors were assumed to be normally distributed. These multivariate normal distributions is usually notated as u~MVN(0,Gu) and e~MVN(0,R) where MVN are denoted as multivariate normal distribution. The SNP effects were calculated using single nucleotide polymorphism-genomic best linear unbiased prediction (SNP-GBLUP) using the SNP-SNP relationship matrix (Lee et al., 2014). This SNP-SNP relationship matrix (SSRM) is based on the genomic relationship matrix (GRM) (Goddard et al., 2011). SSRM was denoted as Gu and GRM as G. The SSRM (Gu) can be calculated using the relationship, Gu = (ZTGŌłÆ1Z)ŌłÆ1 (Lee et al., 2014). The fixed effect was season. The R package, ŌĆ£rrBLUPŌĆØ was used for the analysis (Endelman, 2011).
Estimation of expected current relative selection coefficient
FisherŌĆÖs fundamental theorem of natural selection states that fitness change of any organism per unit time is equal to its genetic variance in fitness at that time. In the linear additive model, therefore, we can easily calculate the additive genetic variance and selection coefficient based on this theorem (Price, 1972; Hartl, 1988; Ewens, 1989). The relative selection coefficient was calculated using the following formula:
Where fitness per genotype is (wAA, wAAŌĆ▓, wAŌĆ▓AŌĆ▓) = (1-s, 1-s/2, 1) and s is the selection coefficient symbol.
(3)
Where i represents ith individual, j represents jth marker or SNPs, Zij represents the ith individuals and jth SNPsŌĆÖ 0, 1, 2 coding. uj represents the SNP effect. The additive genetic variance calculation is a data-driven method which uses the Z matrix, directly.
Equation (3) is based on the FisherŌĆÖs fundamental theorem of natural selection (Frank and Slatkin, 1992). The relative selection coefficient of a given locus is in the range of ŌłÆ1(minimum) to 1(maximum). We assumed the normality of relative selection coefficient and then set the criteria of highly selective SNPs as p-value <0.01 (nearly top 1% SNPs).
Especially, if the SNP markers are under HWE in current generation, s2 = 4u2 according to var(Zi) = 2pq. If we pay heed on the expected relationship of the sign between selection coefficient s and SNP effect u, we can derive that s = 2u.
Characterization of candidate genes under selection regions
We identified the genes which contained significantly selective SNPs and performed gene ontology analysis using the ClueGo plugin of Cytoscape program (Bindea et al., 2009). The gene catalog was retrieved from Ensembl website (www.ensembl.org). In the ClueGo analysis, we used the default parameter except for setting the 2 minimum number of genes in gene ontology (GO) term/Pathway selection and then we corrected p-value through Benjamini-Hochberg method (Benjamini and Hochberg, 1995).
RESULTS AND DISCUSSION
SNP-GBLUP method results and highly selective SNPs
The mean and standard deviation of Holstein milk yield, fat and protein records for parity 1 were 8,845; 1,425, 339; 58 and 283; 44, respectively. We estimated narrow-sense heritability of the milk yield, fat and protein using results of SNP-GBLUP method which were 0.39, 0.45, and 0.40, respectively. The fixed effects (season) of milk yield, fat and protein (kilograms) were (8,655, 8,847, 8,935, 8,907), (325, 342, 344, 343) and (275, 286, 286, 283) for spring, summer, autumn, and winter, respectively. From SNP effects from SNP-GBLUP method, we estimated the selection coefficients of each SNP.
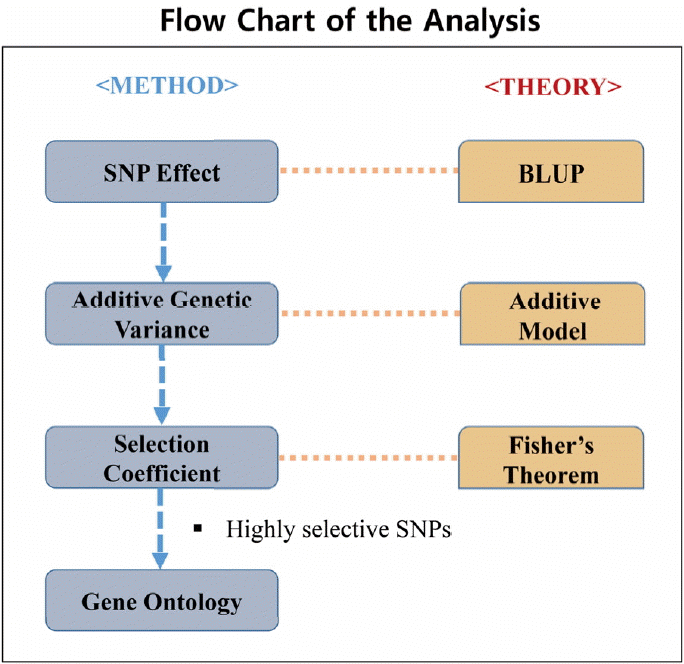
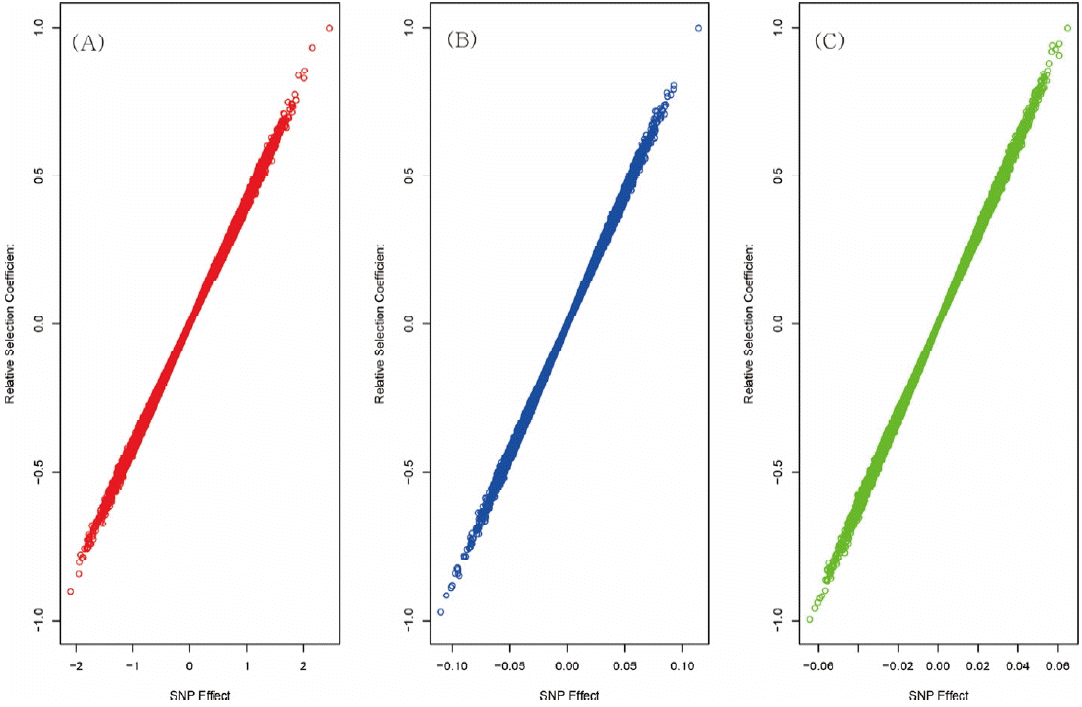
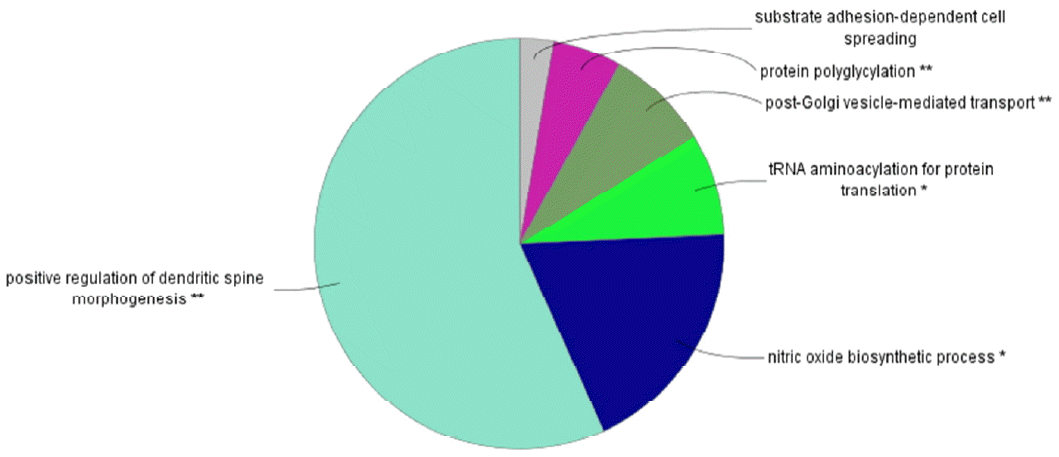
Figure 1 shows the flow chart of the analysis which is designed by theory and method. Figure 2 shows the plot of relative selection coefficient against SNP effect. It implies that the selection coefficient is mainly determined by SNP effect. The sign of relative selection coefficient was inferred from the sign of SNP effect. Figure 3 indicates the diagram of ontology of the genes which contain nearly the top 1% SNPs in the protein contents. We selected the genes containing SNPs with p-value <0.01 (nearly top 1% SNPs) and performed gene ontology. The condition was the default value except for setting 2 as the minimum number of genes in the GO Term/Pathway selection item.
Table 1 illustrates the F1 generationŌĆÖs expected allele frequency change under linear additive model. It demonstrates that allele frequency can be predicted via the SNP effect. Table 2 shows highly selective SNPs and the genes containing them (any p-value <0.001; nearly top 0.1% SNPs). The genes containing very highly selective SNPs with p-value <0.01 (nearly top 1% SNPs) in all traits and p-value <0.001 (nearly top 0.1%) in any traits were phosphodiesterase 4B (PDE4B), serine/threonine kinase 40 (STK40), collagen, type XI, alpha 1 (COL11A1), ephrin-A1 (EFNA1), netrin 4 (NTN4), neuron specific gene family member 1 (NSG1), estrogen receptor 1 (ESR1), neurexin 3 (NRXN3), spectrin, beta, non-erythrocytic 1 (SPTBN1), ADP-ribosylation factor interacting protein 1 (ARFIP1), mutL homolog 1 (MLH1), transmembrane channel-like 7 (TMC7), carboxypeptidase X, member 2 (CPXM2), and ADAM metallopeptidase domain 12 (ADAM12). We inferred the sign of relative selection coefficient from the SNP effect information in Table 1. The positive sign of SNP effect represents that of the selection coefficient and vice versa.
Gene ontology analysis of highly selective SNPs
We chose the highly selective SNPs (p-value <0.01) in milk yield, fat, protein-associated analyses and performed the gene ontology analysis with Cytoscape ClueGo plugin program (Shannon et al., 2003). For milk yield and fat cases, there were no great information about gene ontology. For proteins, significant gene ontologies were dendritic spine morphogenesis and the nitric oxide biosynthetic process with dendritic spine morphogenesis being highly significant. Dendritic spine is the major site of excitatory synaptic transmission in the mammalian brain and is very important in synaptic development and plasticity (Penzes et al., 2003; Tada and Sheng, 2006). The specific genes which produce milk protein and influence the morphogenesis of dendritic spine in the mammalian brain may be a putative and important target of future artificial selection trends in the Holstein cattle.
SNP-GBLUP and selection coefficient
The SNP-GBLUP has merits to predict the SNP effects by assigning the SNP-SNP relationship matrix (Lee et al., 2014). The accurate estimation of the sign of SNP effect as well as its value is crucial to accurately predict the selection coefficient. Thus, we used the SNP-GBLUP rather than SNP-BLUP which assumes the effect being IID (independent and identically distributed) between markers. Not only the sample size but also the accurate prediction of the SNP effect is necessary to predict the relative selection coefficient.
FisherŌĆÖs theorem and best linear unbiased prediction
One of FisherŌĆÖs contributions to population genetics is a fundamental theorem of natural selection. It elucidated selection theory and subsequently breeding science. (Frank and Slatkin, 1992). The theorem indicates that the change of average fitness can be related to genetic variance which is specific to markers like SNPs. Average fitness in the next generation can be designated through selection coefficient in the linear additive model. The fitness change in the next generation can lead to the change of selection coefficient. The linear additive model like BLUP was used to compute the genetic variance of each SNP.
Figure 2 shows that the larger SNP effects, the greater selection coefficients. This finding that the selection coefficients are proportional to the SNP effects, matches the common sense of selection. If one individual had many SNPs with large effects, it would have large breeding values and would be selected by artificial selection. Thus, it seems to be natural that genetic factors like SNPs can determine the selection. It certainly links selection in the population to the breeding programs.
The sign of relative selection coefficient of SNP
The sign of the selection coefficient of a SNP is not explicit. However, the sign of SNP effect is definite. Thus we inferred the sign of relative selection coefficient of a SNP from SNP effect. A positive sign of relative selection coefficient indicates a positive sign of the SNP effect and vice versa. If the sign of a SNP effect were positive, the frequency of the allele coded as ŌĆś2ŌĆÖ would increase and the contribution to the genomic estimated breeding values (GEBVs) would increase. If sign were negative, the situation would be vice versa, i.e. the frequency of the allele coded as ŌĆś0ŌĆÖ would increase by selective breeding.
The features of our study
The characteristics of our paper was: first, we found that the SNP effect in the BLUP model is equivalent to the selection coefficient and is the powerful cause of a populationŌĆÖs allele frequency change; second, we used FisherŌĆÖs theorem and SNP-GBLUP. We adopted FisherŌĆÖs theorem to calculate selection coefficient. SNP-GBLUP which uses the SSRM (SNP-SNP relationship matrix) via GRM to predict the SNP effects.
IMPLICATIONS
The objective of our study was to find the selection coefficient of SNP in the population and find the SNPs which are expected to be highly selective in the next generation. The sign of selection coefficient of SNP was inferred from the sign of SNP effect. The signs of highly selective SNPs (p-value <0.01 or nearly top 1% SNPs) were nearly identical in all traitsŌĆÖ analyses. We found that the selection coefficients of SNPs were linearly proportional to the SNP effects. Especially, selection coefficient would be 2├ŚSNP effect under HWE in the current generation. The significant genes may be crucial in future selection trends of Korean Holsteins.
 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Full text via PMC
Full text via PMC Download Citation
Download Citation Print
Print







